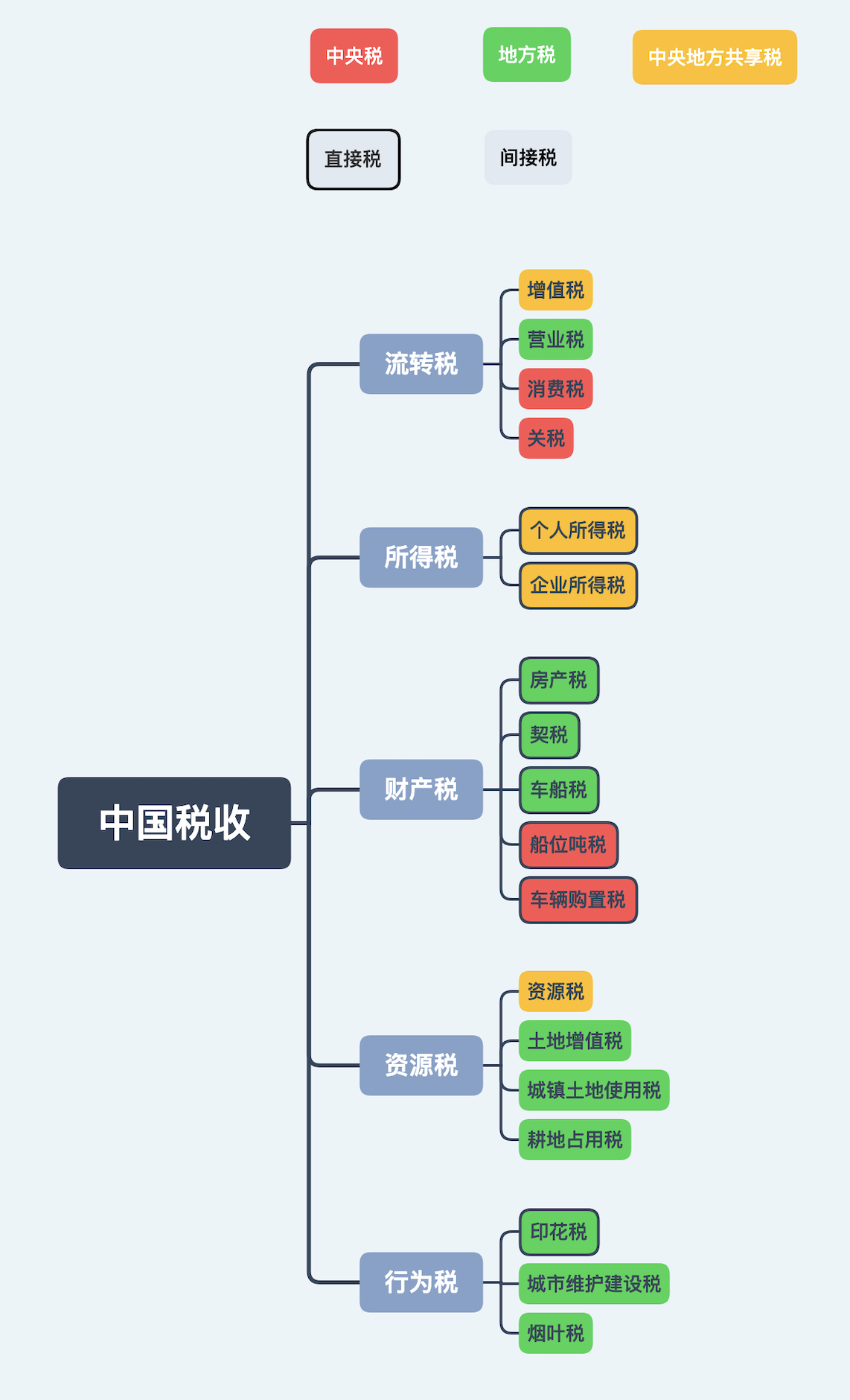
在和一些年轻的数据工程师交流时,我发现一个有趣的现象。
很多人每天都在开发ODS、DWD、DWS、ADS。
熟悉Hive、Spark、Flink、ClickHouse。
却很少认真思考过一个问题:
为什么企业需要数据仓库?
尤其是在AI快速发展的今天。
越来越多的人开始提出类似的问题:
- 有了湖仓一体,还需要数据仓库吗?
- 有了ChatBI,还需要数据仓库吗?
- Agent能够自动生成SQL,还需要数据仓库吗?
在回答这些问题之前,我们需要先回到数据仓库诞生的那个时代。
因为只有理解它为什么出现,才能理解它为什么至今仍然存在。
企业最早并没有数据仓库
今天很多企业的数据架构看起来似乎理所当然:
1 | ERP → 数据仓库 → BI → 报表 |
但实际上,大多数企业最初并没有数据仓库。
在信息化建设初期,企业通常只有几个核心业务系统:
- ERP
- 财务系统
- CRM
- HR系统
当管理层需要数据时,往往直接从业务系统查询。
例如:
销售总监问:
“本月销售额是多少?”
技术人员登录ERP数据库。
执行一条SQL。
得到结果。
似乎没有任何问题。
因为那时:
- 数据量不大
- 系统数量不多
- 分析需求简单
业务系统同时承担:
- 交易处理
- 数据存储
- 数据分析
三种职责。
但随着企业规模扩大,问题开始逐渐暴露。
第一个问题:业务系统不是为分析而设计的
ERP最重要的任务是什么?
是保证订单能够正常流转。
CRM最重要的任务是什么?
是保证客户管理流程正常运行。
MES最重要的任务是什么?
是保证生产过程可控。
这些系统有一个共同特点:
它们都属于OLTP系统(联机事务处理系统)。
其核心目标是:
- 快速写入
- 快速更新
- 高并发事务
而数据分析恰恰相反。
分析系统更关注:
- 大量历史数据
- 多表关联计算
- 聚合统计分析
例如:
业务系统可能需要快速保存一笔订单。
而分析系统则希望统计:
过去三年各区域产品销售趋势。
这是两种完全不同的工作模式。
如果直接在ERP上执行复杂分析:
轻则查询缓慢。
重则影响业务运行。
因此:
业务系统适合处理交易,不适合处理分析。
这是数据仓库存在的第一个原因。
第二个问题:企业的数据是分散的
很多企业管理层都喜欢问这样的问题:
“哪个客户最赚钱?”
看起来很简单。
但实际计算往往涉及多个系统:
销售额来自CRM。
成本来自ERP。
回款来自财务系统。
物流费用来自供应链系统。
如果没有统一的数据平台。
每次分析都需要跨系统取数。
不仅效率低。
而且很容易出现口径不一致的问题。
例如:
销售部门说客户A贡献利润500万元。
财务部门说只有350万元。
双方都认为自己正确。
问题出在哪里?
不是数据错了。
而是计算逻辑不同。
企业真正需要的不是更多数据。
而是统一的数据语言。
这正是数据仓库解决的核心问题之一。
第三个问题:业务系统只关心现在
业务系统关注的是当前状态。
例如ERP中的库存表。
今天库存100件。
明天库存80件。
后天库存120件。
ERP只需要记录当前库存。
但管理层更关心:
- 库存变化趋势
- 历史库存水平
- 周转率变化
这些分析都需要历史数据。
而历史数据往往不会长期保存在业务系统中。
于是企业开始把业务数据持续同步出来。
形成历史快照。
构建分析主题。
这也是数据仓库的重要价值。
它不仅存储数据。
更保存企业经营过程中的历史记忆。
第四个问题:企业需要统一指标
很多企业都有一个经典现象。
开会时讨论同一个指标。
不同部门拿出不同数字。
例如:
“上个月销售额是多少?”
销售部门:
1.2亿元。
财务部门:
1.05亿元。
运营部门:
1.1亿元。
数据部门:
1.15亿元。
每个人都能解释自己的计算逻辑。
但最终没人知道哪个数字才是正确的。
问题本质上不是数据问题。
而是指标问题。
数据仓库建设过程中。
企业第一次开始系统化思考:
- 什么是销售额?
- 什么是利润?
- 什么是客户数?
- 什么是新增用户?
通过统一口径。
企业建立起共同的数据语言。
从某种意义上说:
数据仓库最大的价值不是存储数据,而是统一认知。
数据仓库真正解决了什么?
如果把前面的问题总结一下。
数据仓库解决的并不是简单的数据存储问题。
而是四个核心问题:
第一:
让业务系统专注交易处理。
第二:
打通企业数据孤岛。
第三:
沉淀历史数据资产。
第四:
统一企业指标体系。
因此。
数据仓库的本质不是一个数据库。
而是一套数据组织方法。
是一种让企业能够理解自身经营状况的基础设施。
AI时代,数据仓库为什么依然重要?
最近两年。
很多人开始讨论:
ChatBI。
Data Agent。
自然语言问数。
智能分析。
似乎未来不再需要数据仓库。
但实际上。
这些新技术恰恰更加依赖数据仓库。
我们可以思考一个简单问题:
如果企业内部存在三个版本的销售额。
Agent应该相信谁?
如果客户名称在不同系统中不一致。
Agent应该分析哪个客户?
如果历史数据缺失。
Agent如何完成趋势分析?
如果数据质量存在问题。
Agent如何保证回答正确?
答案很简单。
Agent不会自动创造事实。
Agent只能利用已有事实。
而数据仓库正是企业事实的组织者。
过去:
数据仓库服务BI。
未来:
数据仓库服务Agent。
它的角色会变化。
但其核心价值不会消失。
数据仓库最大的价值,其实是降低沟通成本
很多人认为数据仓库的价值在于技术。
我越来越觉得不是。
数据仓库最大的价值其实是:
降低组织沟通成本。
当企业拥有统一的数据口径时:
销售和财务不再争论数字。
业务和技术不再争论规则。
管理层不再争论结果。
大家能够把精力放在真正重要的问题上:
为什么会这样?
应该怎么办?
而不是:
数字到底哪个对?
从这个角度看。
数据仓库从来不是技术项目。
而是企业管理能力建设的一部分。
写在最后
过去二十年。
数据仓库之所以能够成为企业数据体系的核心。
并不是因为它拥有最先进的技术。
而是因为它解决了企业最本质的问题:
让企业能够用统一的语言理解自己的经营状况。
AI不会改变这一点。
ChatBI不会改变这一点。
Data Agent也不会改变这一点。
未来发生变化的。
只是数据被消费的方式。
而不会是数据被组织的逻辑。
下一篇文章,我们继续讨论另一个关键问题:
BI为什么成为企业数据消费的主流模式?